

티스토리 뷰
VScode와 구글 스프레드 시트 연동하기-1
1. 개요재고 관리 DB는 Google Spread sheet를 통해 관리하고 있다.Google Spread sheet의 DB 파일을 내려받아 VScode 에서 DB 파일의 제품별 URL을 찾아가서 필요한 데이터를 Scraping 하는 방식
arc-viewpoint.tistory.com
4. python code 설정
지금까지 해왔던 내용을 다시 정리하면 아래와 같다.
1. Google Cloud Console(`https://console.cloud.google.com/`)에서 프로젝트를 생성
2. API 및 서비스 대쉬보드에서 **Google Sheets API**를 검색하고 활성화
3. **IAM & Admin** > **Service Accounts**에서 새 서비스 계정 생성
4. 서비스 계정에 대한 키를 생성하고(JSON 형식) 다운로드
5. 스프레드시트에 접근할 수 있도록 서비스 계정 이메일 주소를 스프레드시트 공유 설정에 추가
Google 스프레드시트에서 데이터를 읽고 쓰려면 `gspread`와 `oauth2client` 라이브러리를 설치하여야 한다.
pip install gspread oauth2client
아래의 코드는 gspread를 사용하여 구글 스프레드시트에서 URL을 읽고, 스크래핑한 데이터를 스프레드시트에 기록하는 코드이다.
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import concurrent.futures
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from user_agent import generate_user_agent
# 구글 스프레드시트 인증 및 접근
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
creds = ServiceAccountCredentials.from_json_keyfile_name('your_json_file.json', scope)
client = gspread.authorize(creds)
# URL을 읽어올 스프레드시트, 시트선택 및 URL 리스트 읽기
sheet = client.open("Your Spreadsheet Name").worksheet("sheet Name")
urls = sheet.col_values(3)[1:] # 시작할 열 번호 및 행번
# 스크래핑 데이터를 작성할 스프레드 시트 및 시트 선택
stock_sheet = client.open("Your Spreadsheet Name").worksheet("sheet Name")
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
def scrape_url(url):
# 기존 스크래핑 코드 로직 ...
# 스크래핑된 데이터 반환, 예: [product_code, url, checking, price]
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(tqdm(executor.map(scrape_url, urls), total=len(urls)))
# 스크래핑 결과를 스프레드시트에 쓰기
for row in results:
stock_sheet.append_row(row)
end_time = time.time()
print(f"코드 실행 시간: {end_time - start_time:.2f}초")
1. creds = ServiceAccountCredentials.from_json_keyfile_name('your_json_file.json', scope) → Python 스크립트 파일이 `json_file.json`과 같은 폴더에 있어 파일명만 넣었다.
2. sheet = client.open("Your Spreadsheet Name").worksheet("sheet Name") → 제품별 URL을 찾아가서 필요한 데이터를 Scraping 하는 방식이기 때문에 아래 코드에는 URL을 읽어올 스프레드시트(파일명) 및 시트를 반영하였다.
3. urls = sheet.col_values(3)[1:] → 시트 내 URL을 읽어올 시작위치 선택
4. `stock_sheet = client.open("Your Spreadsheet Name").worksheet("sheet Name")` 스크래핑 데이터를 작성할 파일명과 시트선택
5. 실행 결과
코드 실행 결과 아래와 같은 오류 메시지가 나온다.
해석해보면 write 요청의 할당량 그리고 사용자별 분당 write 요청 한도가 넘었다고 한다.
- 에러 메시지 -
gspread.exceptions.APIError: APIError: [429]: Quota exceeded for quota metric 'Write requests' and limit 'Write requests per minute per user' of service 'sheets.googleapis.com' for consumer 'project_number:xxxxxxxxxxxx'
관련 문서에 따르면 구글시트 API의 읽기 및 쓰기의 요청수의 제한이 있다.
https://developers.google.com/sheets/api/limits?hl=ko
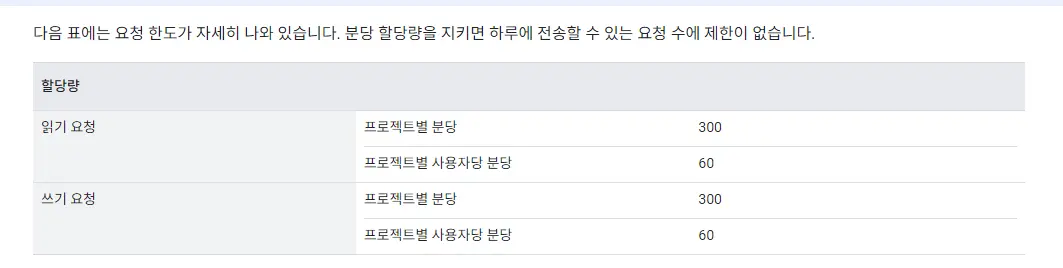
6. 대안
약 1,200 페이지를 방문하고 데이터를 읽어오는 데는 문제가 없지만, 구글 시트에 넣는데 문제가 있는 것인데 몇 가지 대안을 가지고 테스트를 해보았다. 물론 API를 유료로 전환하여 사용량 한도를 확대하면 되겠지만 구글시트가 DB로 최적인지 확신이 없기 때문에 유료 전환은 고려하지 않았다.
1. 데이터를 1행씩 작성하는 것이 아니라 한꺼번에 작성하기.(1건의 요청으로 구글api를 사용하기)
2. 요청수 제한을 준수하여 50건 구글 시트에 쓰고 1분 휴식 후 쓰기
3. 데이터 저장은 excel에 저장하기
1번으로 실행하기 위해 데이터 쓰기 코드를 아래와 같이 수정하여 실행.
stock_sheet.append_rows(results)
실행 결과 스크래핑 완료 후 접속 시작하자 마자 호스트로부터 강제 연결 해제 당했다. 아래 오류 참고.
- 에러 메시지 -
urllib3.exceptions.ProtocolError: ('Connection aborted.', ConnectionResetError(10054, '현재 연결은 원격 호스트에 의해 강제로 끊겼습니다', None, 10054, None))
이는 구글에서 강제 연결 해제한 것으로 판단된다.
2번으로 실행을 위해 코드를 아래와 같이 수정하여 실행하였다.
count = 0
for result in results:
if count >= 50:
time.sleep(60) # 1분 동안 휴식
count = 0 # 카운터 초기화
stock_sheet.append_row(result) # 데이터 한 건씩 추가
count += 1
결과는 시간이 너무 많이 소요된다.
3번의 경우 기존에 하던 방식과 차이점은 URL을 읽어오는 부분을 자동화 한 점이고 결과물은 저장방식은 excel에 저장하기 때문에 동일하다. 가장 시간적으로 좋은 방법이다.
excel_filename = 'scraped_data.xlsx'
df.to_excel(excel_filename, index=False)
7. 종합
기존 방식(아래)보다는 조금 자동화가 되긴 하였다.
1. Google Spread sheet의 DB 파일 내려받기(URL이 있는 파일)
1. VScode Scraping
2. CSV Output
3. Google Spread sheet에 upload
1번이 생략되었고 3번에서 excel 파일을 구글시트에 복사 붙여 넣기만 하면 된다.
다음은 aws를 이용한 추가적인 자동화 작업을 시도해 볼 예정이다.
'Project > Stock Management' 카테고리의 다른 글
| VScode와 구글 스프레드 시트 연동하기-1 (0) | 2024.04.29 |
|---|
- Total
- Today
- Yesterday
- model context protocol
- docker compose
- 고양장항신혼희망타운
- chromedriver버전오류
- kc인증
- Git
- 도커
- OpenAI
- vscode 구글시트 연동
- 티스토리챌린지
- 주택청약
- GitHub
- Google sheet
- Selenium
- IMPORTRANGE
- 오블완
- chatGPT
- 구글시트
- 챗gpt
- scraping
- This version of ChromeDriver only supports Chrome version
- 청약통장
- chrome버전
- Python
- 청약제도
- notebooklm
- docker
- 버전제어
- MCP
- claude desktop
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |